Automated Recovery of Issue-Commit Links Leveraging Both Textual and Non-textual Data
Introduction
Issue reports document discussions around required changes in issue-tracking systems, while commits contain the actual code changes in version control systems. Recovering links between issues and commits facilitates many software evolution tasks such as bug localization, defect prediction, software quality measurement, and documentation.
A previous study on over half a million GitHub issues showed that only about 42.2% of issues are manually linked by developers to their related commits. Automating the linking of commit-issue pairs can significantly improve software maintenance tasks. However, current state-of-the-art approaches suffer from low precision, leading to unreliable results, and perform poorly when there's a lack of textual information in commits or issues.
This article presents Hybrid-Linker, an enhanced approach that overcomes these limitations by exploiting both textual and non-textual data channels:
- A non-textual-based component that operates on automatically recorded metadata of commit-issue pairs
- A textual-based component that analyzes the textual content of commits and issues
By combining results from these two classifiers, Hybrid-Linker makes the final prediction, with one component filling gaps when the other falls short.
Motivating Example
Let's look at a practical example to understand the challenge. Consider an issue from the Apache Flink project:
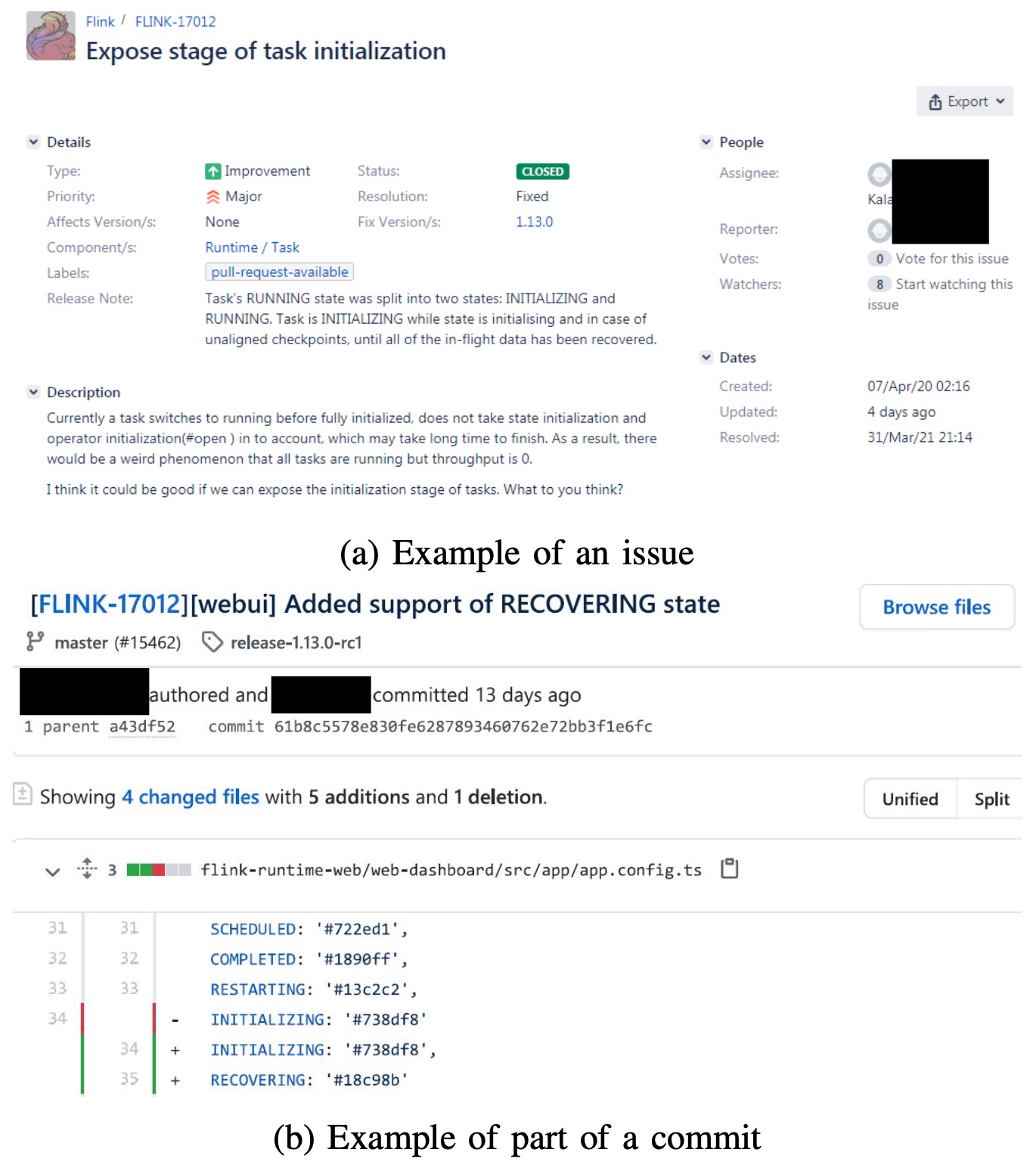
The issue titled "copy method logicalaggregate not copying indicator value properly" lacks compelling similarity between its description text, release notes, and the corresponding commit message. Due to this lack of textual similarity, previous approaches like FRLink and DeepLink struggle to discover the connection between this issue and its commit.
This example highlights the need to extract knowledge from both textual and non-textual information channels of issues and commits to improve link recovery.
Approach
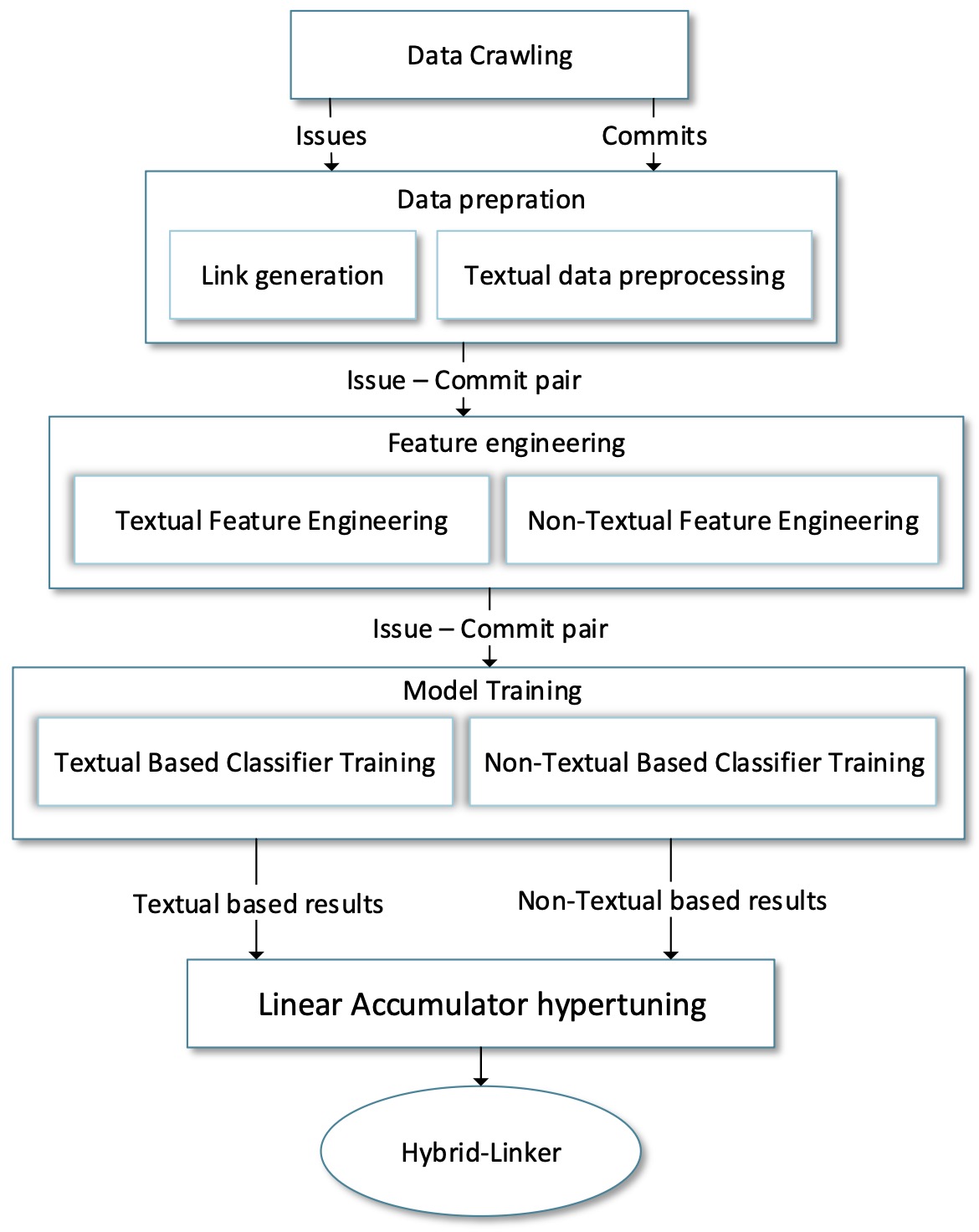
Hybrid-Linker follows five main steps:
1. Data Crawling
The approach starts with collecting data from issue tracking systems and version control systems, including code diff data which requires special handling due to its large volume.
2. Data Preparation
Two essential preparation steps are performed:
Link Generation
- True Links: Issue-commit pairs already linked by developers
- False Links: Generated by pairing commits with issues other than the ones they're already linked to
- To address dataset imbalance, the approach follows criteria from previous works (comparing submission dates) and applies data balancing techniques
Textual Data Preprocessing
- Standard NLP techniques are applied to natural language text: tokenizing, removing stop words, and stemming
- For code diff data, only identifiers (method and variable names) are extracted as they carry the most valuable information about changes
3. Feature Engineering
Textual Feature Engineering
- The TF-IDF technique is applied to natural language text data of commits and issues and the code diff textual data separately
- Three vectors are generated and concatenated to create one textual feature vector per data point
Non-textual Feature Engineering
- Highly correlated columns are reduced to avoid redundancy
- Categorical data is transformed and optimized to avoid sparse matrices
- Temporal data (dates) is preserved as important features
4. Model Training
Two classifier components are trained:
Textual Classifier Model
Multiple classification models are trained and evaluated:
- Decision Tree
- Gradient Boosting
- Logistic Regression
- Stochastic Gradient Descent
Non-textual Classifier Model
Both single and ensemble models are trained:
- Simple methods: Gradient Boosting, Naive Bayes, Generalized Linear, Random Forest, XGBoost
- Ensemble methods: Various combinations of the above models
5. Linear Accumulator Hyper-tuning
The final prediction combines results from both classifiers using a linear accumulator function:
P_final = α × P_non-textual + (1 − α) × P_textual
The α hyperparameter is tuned for each project to produce optimal results.
Evaluation
Research Questions
- RQ1: How effective is Hybrid-Linker compared to state-of-the-art approaches?
- RQ2: How to combine the two components to achieve the best outcome?
- RQ3: What is the effect of each component on the outcome?
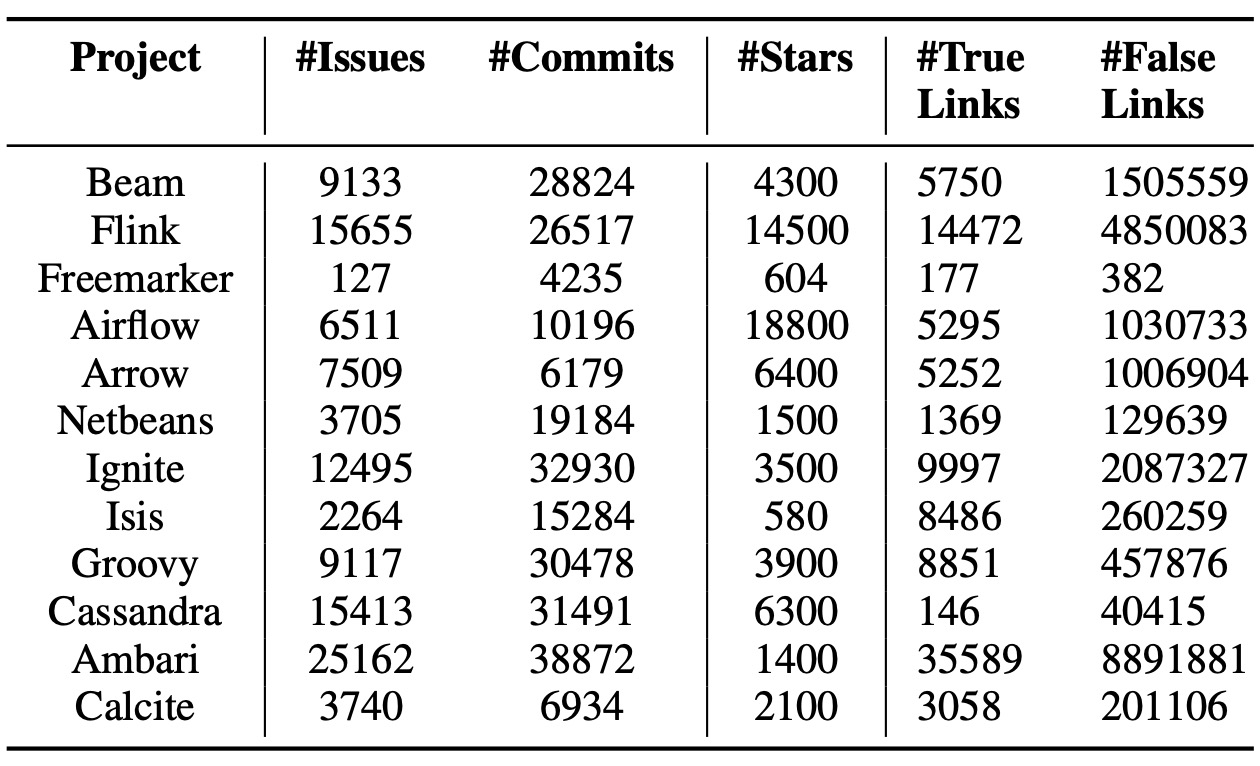
Dataset and Metrics
The study used 12 Apache projects selected based on:
- Having repositories with more than 500 stars
- Having diverse numbers of issues
Evaluation metrics included Precision, Recall, and F-measure, using five-fold cross-validation.
Results
RQ1: Effectiveness Compared to State-of-the-Art
For the textual data, we found out that Gradient Boosting is the best option and for non-textual data we went with the ensemble
of Gradient Boosting and XGBoost.
Performance of the approach across projects:
| Approach | Recall | Precision | F-measure |
|---|---|---|---|
| Hybrid-Linker | 90.14% | 87.78% | 88.88% |
| DeepLink | 60.09% | 68.81% | 62.87% |
| FRLink | 96.86% | 53.61% | 67.67% |
Hybrid-Linker outperformed:
- FRLink by 31.3% regarding F-measure
- DeepLink by 41.3% regarding F-measure
Additionally, Hybrid-Linker was significantly more efficient, requiring far less training time than DeepLink. For instance, training on the Airflow project took only 25 minutes for Hybrid-Linker versus 7 hours for DeepLink.
RQ2: Optimal Component Combination
Each project required a different value of α for optimal results:
- Average α value across all projects: 0.66
- Most projects had α above 0.5, indicating non-textual components played a more important role
- Projects with extremes: Calcite (α = 0.95) and Ambari (α = 0.45)
RQ3: Component Effect Analysis
| Model | Recall | Precision | F-measure | Std Dev |
|---|---|---|---|---|
| Hybrid | 90.14% | 87.78% | 88.88% | 3.00 |
| Textual | 80.83% | 80.92% | 80.82% | 5.83 |
| Non-textual | 85.57% | 91.63% | 88.36% | 3.10 |
Key findings:
- The textual model had the lowest performance and highest standard deviation
- The non-textual model outperformed the hybrid model in precision
- The hybrid model achieved the highest recall and F-measure scores with the lowest standard deviation
Example Success Case
An example shows where the model successfully recovered a true link when textual information was insufficient:
| Issue Information | Commit Information |
|---|---|
| Created date: 2014-12-08 | Author time date: 2014-12-10 |
| Summary: "copy method logical aggregate not copying indicator value properly" | Message: "[ calcite-511 ] copy method logical aggregate not copying indicator value properly fixes # 26" |
| Bug: 1, feature: 0, task: 0 | DiffCode: "logical aggregate .java..." |
Despite few textual similarities, the non-textual component compensated for this shortcoming and predicted the correct connection.
Conclusion
Hybrid-Linker leverages both textual and non-textual information to recover links between issues and commits. By tuning the importance of each information channel (via parameter α), it achieves superior performance compared to existing approaches, especially in cases with limited textual information.
The approach outperforms competing methods with:
- Higher accuracy (F-measure improvement of 31-41%)
- Shorter training time
- Better adaptability across different projects
The research demonstrates that non-textual information is often critical to accurate link prediction, particularly when textual similarities are minimal.
Future work will focus on identifying new features from different bug tracking and version control systems, and investigating other classifier architectures.
To check the paper click on following link or download directly from following link.
Citation:
@inproceedings{mazrae2021automated,
title={Automated recovery of issue-commit links leveraging both textual and non-textual data},
author={Mazrae, Pooya Rostami and Izadi, Maliheh and Heydarnoori, Abbas},
booktitle={2021 IEEE International Conference on Software Maintenance and Evolution (ICSME)},
pages={263--273},
year={2021},
organization={IEEE}
}